




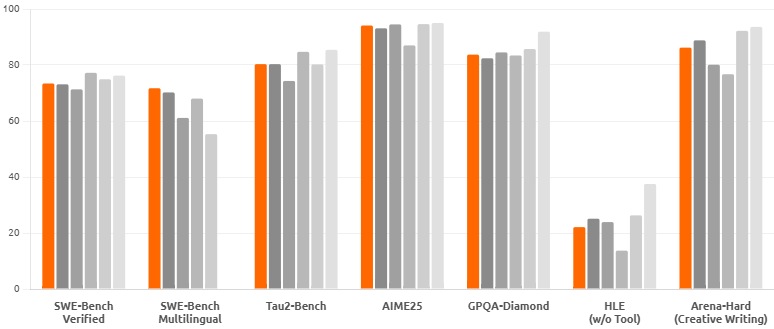
XiaomiがMiMo-V2-FlashをMITライセンスで公開した。総パラメータ数309B、アクティブパラメータ数15BのMoEモデルで、128トークンのスライディングウィンドウと5:1のハイブリッド比率を採用している。数学競技AIME 2025と科学知識ベンチマークGPQA-Diamondでオープンソースモデルのトップ2にランクインした。
SWE-bench VerifiedおよびMultilingualではオープンソースモデル中第1位を獲得し、それぞれ73.4%、71.7%のスコアを記録した。256kコンテキストウィンドウを提供し、推論速度は秒速150トークン、コストは入力トークン100万あたり0.1ドル、出力トークン100万あたり0.3ドルである。
モデルウェイトはMITライセンスの下でHugging Faceで利用可能で、推論コードはSGLangに貢献された。
From: ![]() Introducing MiMo-V2-Flash
Introducing MiMo-V2-Flash
【編集部解説】
XiaomiがリリースしたMiMo-V2-Flashは、AI開発の潮流を象徴する一手と言えます。総パラメータ309Bというスペックだけ見れば巨大ですが、実際に動作するのは15Bのみという「Mixture of Experts(MoE)」アーキテクチャを採用しています。これは、複数の専門家が得意分野で協力するチームのような仕組みで、全ての計算リソースを常に使うのではなく、タスクに応じて最適な専門家だけを呼び出す設計です。
技術面で特筆すべきは、ハイブリッドアテンション機構とマルチトークン予測(MTP)の組み合わせです。通常、大規模言語モデルは文脈を記憶するために膨大なメモリ(KVキャッシュ)を必要としますが、MiMo-V2-Flashは128トークンという狭い窓を5:1の比率でグローバルアテンションと組み合わせることで、メモリ使用量を約6分の1に削減しました。さらにMTPにより、1回の推論で複数のトークンを並列予測することで、実効速度を2〜2.6倍に高めています。
コスト面での革新性も見逃せません。入力トークン100万あたり0.1ドル、出力0.3ドルという価格設定は、主要な商用モデルと比較して大幅に低コストです。これまで高額なAPI料金がネックだった企業や個人開発者にとって、高性能モデルへのアクセスが現実的な選択肢になります。
長期的な視点では、このリリースがオープンソースAIエコシステムに与える影響は計り知れません。MITライセンスでの公開により、研究者や開発者は自由に改良・商用利用が可能です。SGLangへの推論コードの貢献も初日から行われており、Xiaomiがコミュニティ駆動の開発を重視していることが伺えます。
256Kという長大なコンテキストウィンドウは、数百ラウンドにわたるエージェント対話や、大規模コードベース全体の解析を可能にします。これにより、従来は不可能だった複雑な自動化タスクや、エンタープライズレベルのコード生成が現実のものとなります。SWE-bench Verifiedで73.4%という数字は、実際のソフトウェアエンジニアリングタスクにおいて、人間のエンジニアを補助するレベルに達していることを示唆しています。
スマートフォンからIoTデバイス、自動車まで幅広いハードウェアエコシステムを持つXiaomiにとって、自社AIモデルの開発は製品統合の基盤となり得ます。今後、同社製品群にMiMoシリーズが組み込まれていく可能性も十分に考えられるでしょう。
【用語解説】
MoE (Mixture of Experts)
複数の専門化されたニューラルネットワーク(エキスパート)を組み合わせたアーキテクチャ。入力データに応じて最適なエキスパートを選択的に活性化することで、総パラメータ数は大きくても実際の計算量を抑えられる。
スライディングウィンドウアテンション
直近の限定された範囲(ウィンドウ)内のトークンのみに注意を向けるアテンション機構。メモリ効率が高く、長い文脈でも計算コストを一定に保てる。
KVキャッシュ
言語モデルが過去の文脈を記憶するために保持するキー(K)とバリュー(V)の情報。長い文脈では膨大なメモリを消費するため、効率化が重要な課題となる。
マルチトークン予測 (MTP)
1回の推論で次の1トークンだけでなく、複数のトークンを同時に予測する手法。並列処理により推論速度を大幅に向上させることができる。
SWE-bench
ソフトウェアエンジニアリング能力を測定するベンチマーク。実際のGitHubリポジトリから収集された問題を解決できるかを評価する。
コンテキストウィンドウ
言語モデルが一度に処理できる入力テキストの最大長。256Kトークンは約20万語に相当し、長文書や大規模コードベース全体を扱える。
MOPD (Multi-Teacher Online Policy Distillation)
複数の教師モデルから学生モデルへ知識を蒸留する強化学習手法。従来のSFT+RLパイプラインより少ない計算資源で高性能を実現する。
【参考リンク】
Hugging Face – MiMo-V2-Flash(外部)
MITライセンスで公開されたモデルウェイトのリポジトリ。ベースモデルを含む各種バージョンがダウンロード可能
SGLang GitHub(外部)
高性能言語モデル推論フレームワーク。Xiaomiが推論コードを初日から貢献しコミュニティと協力
【参考記事】
MiMo-V2-Flash: 309B Open Source AI Model | 150 tok/s Fastest LLM(外部)
公式技術ページ。309Bパラメータ、秒速150トークン、入力0.1ドル/出力0.3ドルのコスト詳細を掲載
Xiaomi MiMo-V2-Flash Arrives Strong: Wielding 309B Parameters of AI(外部)
MoEアーキテクチャとハイブリッドアテンション機構を詳細解説。5:1比率の技術的特徴を分析
Xiaomi MiMo-V2-Flash: Complete Guide to the 309B Parameter MoE Model(外部)
SWE-bench73.4%達成とMOPDパラダイムを解説。従来の1/50未満の計算資源で同等性能実現
Mixture of Experts Explained – Hugging Face(外部)
MoEアーキテクチャの基礎概念と実装方法。計算効率を保ちながらモデル容量を拡大する仕組みを説明
【編集部後記】
MiMo-V2-FlashのMITライセンス公開は、誰もが最先端のAIモデルに触れられる時代の到来を象徴しています。従来は高額なAPI料金がネックだった方も、この圧倒的なコスト効率なら気軽に試せるのではないでしょうか。皆さんはどんなプロジェクトでこのモデルを活用してみたいですか?コード生成、長文解析、それとも独自のエージェント開発でしょうか。
Hugging Faceから自由にダウンロードできる今、実際に手を動かしてみることで見えてくる可能性もあるかもしれません。オープンソースコミュニティへの貢献も含めて、一緒にこの技術の未来を探ってみませんか。


































