


「誰がそれを言ったか」は、発言の内容と同じくらい重要な情報です。会議の議事録を作る際、上層部が賛同したのか、反対意見はどの部署から出たのか。そうした文脈が失われると、AIによる要約は”何を話したか”は拾えても”会議が何を決めたか”は掴みきれません。4月9日に提供が始まるLINE WORKS AiNoteのアップデートは、最大30名の話者を自動識別し、そのデータを外部システムに渡すAPIを加えることで、会議記録を「組織の意思決定ログ」へと引き上げようとするものです。その2つの機能が持つ意味を掘り下げます。
LINE WORKS株式会社は2026年4月7日、AI議事録作成ツール「LINE WORKS AiNote」(以下AiNote)の大幅アップデートを発表した。4月9日より提供を開始する。主な追加機能は3点だ。
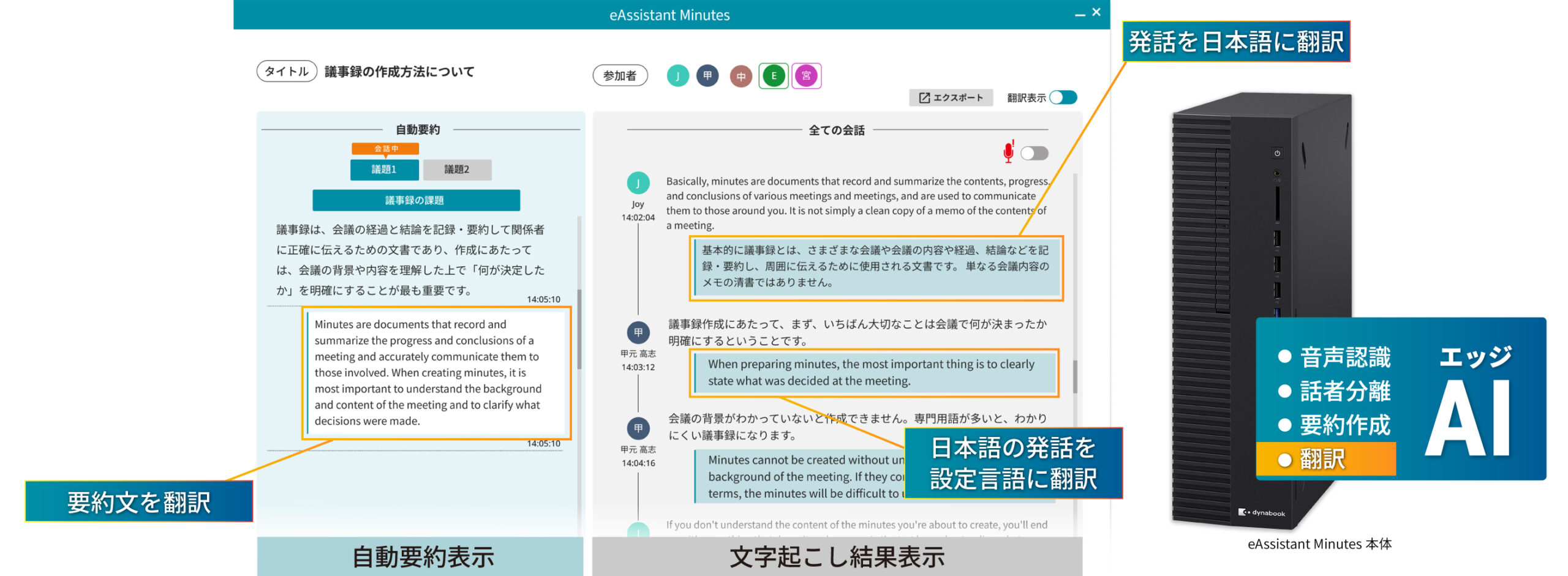
①話者識別技術を用いた「自動話者認識」機能を新たに追加し、1回の会議につき最大30名の発話者を識別して会議記録に自動で反映する。
②「AI要約」機能を拡張した「次のステップ」により、会議内のToDo事項をワンタップで抽出可能になった。
③外部連携用APIの提供を開始し、自社システムや外部サービスからの会議データの取得・操作が可能になる(対象プラン:エンタープライズ)。
From: ![]() LINE WORKS AiNote 大幅アップデートに関するプレスリリース(2026年4月7日)
LINE WORKS AiNote 大幅アップデートに関するプレスリリース(2026年4月7日)
アイキャッチ画像:LINE WORKS Corp.公式プレスリリースより引用
【編集部解説】
「話者分離」と「話者識別」は別のものである
まず、技術的な前提を整理しておく必要があります。
AI議事録ツールが音声を処理するとき、「話者分離」と「話者識別」は、見かけ上は似ていても根本的に異なる処理です。話者分離は「ここで声が変わった」という区切りを検出するものです。一方、話者識別はその先の「この声は田中部長である」という名前の紐付けまでを行います。
AiNoteが今回追加した「自動話者認識」は、この後者にあたります。既存の高精度な話者分離機能に、声の特徴量(ボイスプリント)をアドレス帳の社内メンバー情報と照合する仕組みを組み合わせたものと考えられます。
事実、前身であるCLOVA Speechは国際コンペティションDIHARD3のTrack 1(話者分離部門)において2021年に世界3位を獲得しています。
この区別は重要です。話者分離だけの議事録は、後から人間が「この声は誰だったか」を手作業で書き換える必要がある。識別まで自動化されることで、その手間が消えるだけでなく、AI要約の質そのものが変わります。
話者ラベルがないと、AI要約は「会議の空気」を読めない
ここが今回のアップデートの核心です。
簡易的なボイスレコーダーやアプリなどで録音した会議音声をそのまま汎用の文字起こしAIにかければ、「何が話されたか」はテキスト化できます。しかし、「誰がそれを言ったか」が欠落した議事録からAIが要約を生成すると、発言の重みが均一化されてしまいます。
たとえば、「この方針で進めましょう」という発言。それが決裁権を持つ経営層から出たのか、若手社員の提案なのかで、その一文の組織的な意味はまったく異なります。話者ラベルのない要約は「こういう話が出た」とは伝えられても、「会議として何を決めたか」を正確に伝えることができません。
この問題は、参加者が増えるほど深刻になります。5〜6人程度の会議なら、議事録を読む側も声の主を推測できることが多いかもしれません。ですが、10人、20人規模の部門横断会議になると、話者情報のない議事録はほぼ使い物になりません。
APIが開く「会議データの外部接続」という地平
今回のアップデートで長期的に大きな意味を持つのが外部連携用APIの提供開始です。
APIを通じて、ノート一覧の取得、詳細内容の取得、文字起こし時間やAI要約の使用状況の照会が可能になります。対象はエンタープライズプランに限定されますが、これにより会議データは「AiNoteの中に閉じた記録」から「組織のワークフローに接続された構造化データ」へと変わります。
具体的には、プロジェクト管理ツール(Jira、Asana等)への自動タスク連携、CRMへの商談記録の自動反映、社内ナレッジベースへの蓄積といった活用が想定されます。会議で「来週までに〇〇を提出する」と決まったことが、APIを経由してタスク管理ツールに自動登録されるといったワークフローが現実的になります。
「会議の記録」から「組織の意思決定ログ」へ
話者識別とAPIという2つの機能を組み合わせて見えてくるのは、会議データの位置づけの変化です。
従来の議事録は「会議の内容を後から確認するための記録」でした。しかし、誰がどのような立場で何を発言し、何が決定されたかが構造化されたデータになると、それは「組織の意思決定プロセスを追跡可能にするログ」に変わります。
このシフトは、AI活用の文脈でも重要です。プレスリリースが述べるように、議事録や会議データは「AIの学習データや、組織ナレッジとして活用可能な”情報資産”」としての価値を持ちます。話者情報のない要約テキストと、誰が何を言ったかが紐付いた構造化データでは、後者の情報としての密度が段違いです。
ただし、ここには留意すべき点もあります。会議の発言がすべて記録・識別・蓄積されることに対して、参加者の心理的な影響、たとえば率直な意見が出にくくなるリスクは、技術の外側で組織が考えるべき課題です。ツールの導入は技術的な問題ですが、その運用ルールの設計は組織文化の問題であり、後者を軽視すると、かえって会議の生産性を下げてしまう可能性もあります。
今後の焦点は、この「構造化された会議データ」をどれだけ多くの業務プロセスと接続し、実際の意思決定スピードの向上につなげられるかでしょう。AiNoteの今回のアップデートは、その第一歩を踏み出すものですが、APIで取得できる項目がまだノート一覧・詳細・削除・利用状況の照会に限定されている点は、今後の拡張余地を示唆しています。話者別の発言データの抽出や、要約結果のプログラマティックな取得が可能になれば、活用の幅はさらに広がるはずです。
【用語解説】
話者分離(スピーカーダイアライゼーション)
音声ファイル内に複数の話者が存在する場合に、「Speaker A」「Speaker B」のように匿名ラベルを付けて発言区間を分割する技術。「誰が話しているか」ではなく、「ここで声が変わった」という区切りを検出する処理が中心。
話者識別
話者分離によって分けられたセグメントを、既知の人物データベース(声紋・ボイスプリント)と照合し、「Speaker Aは田中部長」のように実名と紐付ける技術。話者分離の上位レイヤーにあたり、事前に登録された声のデータが必要。
ボイスプリント(音声特徴量)
声の高さ・質・共鳴などの音響特性を数値化したもの。個人の声の「指紋」に相当し、話者識別システムはこの特徴量を照合することで発言者を特定する。
CLOVA Speech
LINE WORKS株式会社が開発・採用する音声認識AIエンジン。国際コンペティション「DIHARD3(2021年)」のTrack 1(話者分離部門)において世界3位を獲得した実績を持つ。LINE WORKS AiNoteの音声処理基盤として使われている。
DIHARD3(ダイハード3)
難条件下での話者分離技術を競う国際コンペティションの第3回大会(2021年開催)。レストランや臨床インタビューなど11の多様な音響環境から収集した音声データを使い、話者分離システムの精度を競う。世界の研究機関・企業が参加する事実上の業界標準ベンチマーク。
【参考リンク】
LINE WORKS AiNote 製品ページ(外部)
AiNoteの機能概要・料金プラン・導入事例を掲載する公式製品ページ。
LINE WORKS 株式会社 公式サイト(外部)
ビジネス向けコミュニケーションプラットフォームを提供するLINE WORKS社の公式サイト。
DIHARD3 Challenge 公式サイト(外部)
話者分離の国際コンペティションDIHARD3の公式サイト。ルール・データセット・結果を掲載(英語)。
【参考記事】
LINE WORKS AiNote 解説記事 — Rimo Voice(外部)
競合サービスであるRimo VoiceによるAiNoteの機能・特徴の解説記事。
What Is Speaker Diarization and How Does It Work? — AssemblyAI Blog(外部)
話者分離の4ステップを詳述した技術解説。音声検出からクラスタリングまでのプロセスを網羅(英語)。
Otter.ai Speaker Identification: Accuracy, Setup, and Limitations — summarizemeeting.com(外部)
第三者評価サイトによるOtter.aiの話者識別精度の検証。人数別の精度変化と実用上限を分析(英語)。
Speaker Diarization Technology — Phonexia(外部)
音声特徴量(ボイスプリント)の生成からクラスタリングに至る技術プロセスの詳細ドキュメント(英語)。
What Is Diarization? — Gladia(外部)
話者分離のVAD→セグメンテーション→エンベディング→クラスタリングのプロセスを図解。単一マイク録音での精度制約も解説(英語)。
AI議事録ツール比較2026 — ailead Blog(外部)
2026年時点の日本のAI議事録市場を「議事録特化型」vs「カンバセーションインテリジェンス型」に分類して比較。
【関連記事】



【編集部後記】
会議の発言が「記録される」ことと、「誰の発言か特定される」ことの間には、想像以上の距離があります。その距離を技術が埋めたとき、私たちの会議での振る舞いはどう変わるのでしょうか。
ツールを入れるかどうかは技術の問題ですが、どう使うかは組織の文化そのものが問われる領域です。議事録が「記録」から「資産」に変わる条件を、それぞれの現場で探っていく段階に来ているのかもしれません。








