




Google ColabでStable Diffusion Web UIを利用すれば、ほぼ無制限に大量の画像を生成できます。導入方法や使い方、利用の制限時間、仮想環境であることによる注意点も解説します。
Stable Diffusionとは?
「Stable Diffusion(ステーブルディフュージョン)」は、2022年8月にイギリスの企業「Stability AI(スタビリティエーアイ)」によってリリースされた、商用利用可能なオープンウェイトの画像生成AIです。
これは「拡散モデル」と呼ばれる機械学習アルゴリズムを基盤としています。拡散モデルとは、ランダムなノイズ画像から、大量の画像から学習したデータを元に少しずつノイズを取り除いていくことで、指示(プロンプト)に合った画像を生成する技術です。Stable Diffusionの特徴は以下の点にあります。
- オープンウェイト: 学習済みのモデルが公開されているため、研究者や開発者が自由に改良や拡張が可能
- 最小限のリソース: 比較的少ないコンピューティングリソースで高品質な画像生成が可能
- 多様な応用: テキストから画像生成(Text-to-Image)だけでなく、画像から画像生成(Image-to-Image)、画像修復など幅広い機能をサポート
- コミュニティによる発展: 世界中の開発者によって様々なバージョンやカスタムモデルが開発され続けている
他のAI画像生成ツール(DALL-E 、Midjourney等)と比較すると、Stable Diffusionはローカル環境で動作させることができる点が大きな特徴です。これにより、パソコンに導入さえできてしまえばインターネット接続がなくても使用でき、プライバシーを保ちながら無制限に画像生成が可能になります。
オープンウェイトであるため、様々な企業がStable Diffusionを利用したサービスを展開したり、個人のパソコンで自由に利用することが可能です。アーティスト、デザイナー、マーケティング担当者、そして創作を楽しみたい一般ユーザーまで、幅広い層に活用されています。
画像生成には「プロンプト」と呼ばれる、AIに対する指示文を入力する必要があります。正式な呼び名ではありませんが「呪文」と呼ばれることも多いです。
Stable Diffusionを利用するには大きく分けて3つの方法があります。
1.クラウドAPI(Dream Studio)を利用する
無料でStable Diffusionを体験できる
継続的な利用にはサブスク加入が必須
2.GPUクラウドサービス(Google Colab)を利用する
一部制約はあるが大量生成すればコスパは良い
外部の環境に依存する点が多く、設定がやや複雑
☆本記事で紹介☆
3.ローカル環境で利用する
導入さえできてしまえば無制限に使える
要求されるPCスペックや知識のハードルが高い
今回は「2.GPUクラウドサービス(Google Colab)を利用する」方法について解説していきます。
7/11追記
Stability AIより規約更新が発表され、7/31以降、あらゆる性的コンテンツの生成が禁止となりました。詳しくは以下の記事をご確認ください。
※本記事の内容は2025年7月時点の情報です。大きな変更点は随時更新していきますが、モデルやUI、料金体系などはの詳細は必ず公式サイトや最新の情報も併せてご確認ください。
目次
導入方法
Google Colab(正式名称Google Colabratry)はGoogle社が提供している、誰でも簡単にPythonでのプログラミングができるJupyter notebook形式のGPUクラウドサービスでの一種です。
今回ご紹介するStable Diffusionを利用するための最もメジャーなUIである「AUTOMATIC1111」はオープンソースプロジェクトとしてGitHub上で開発されており、「AUTOMATIC1111」とは開発者のユーザー名で、正式な名称は「Stable Diffusion Web UI(by AUTOMATIC1111)」となります。
「AUTOMATIC1111」はPythonで開発されているため、Google Colabはまさにうってつけというわけです。
2025年5月現在、Stable Diffusion利用者増加のためGoogle Colabの無料版はStable Diffusionをサポート対象外としています。利用が制限されたり、動作が不安定になったりする可能性がありますので、可能であれば有料版の登録をしましょう。
加えて、Google Colabの仕様上、設定やデータは保存されないため、接続が切れるたびに最初からやりなおす必要があります。無料版では上記の理由などで突然セッションが切断されて画像が消えてしまったりするため、必ず気に入った生成画像はすぐ保存するようにしましょう。
まずはGoogle Colabにアクセスしましょう。
そうしたらまずこのようなウィンドウが出てくると思いますが、これは一旦キャンセルするか、ウィンドウの外をクリックして閉じてください。
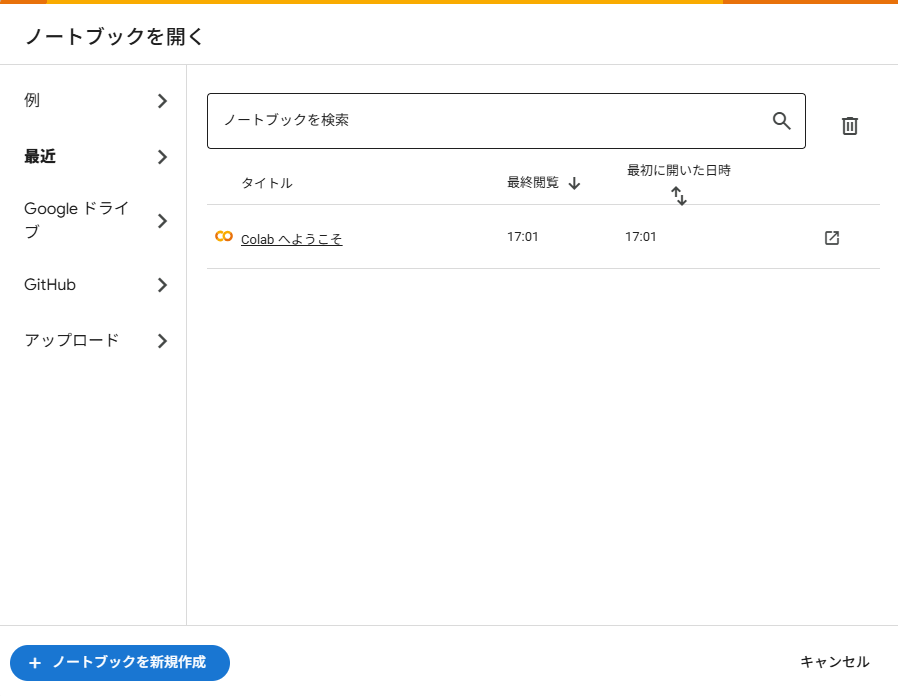
次は画面左上の「ファイル」をクリックして「新しいノートブック」を選択してください
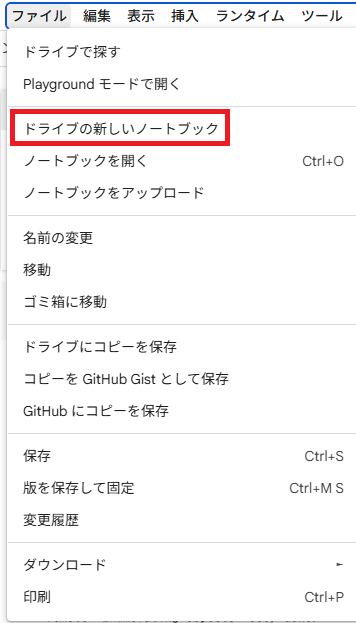
そうしたらコードを実行する画面になります。左上の「Untitled0.ipynd」のところを任意の名前に変更しておくと後から判別しやすくなります。
左上の「ランタイム」タブから「ランタイムのタイプを変更」を選択します。
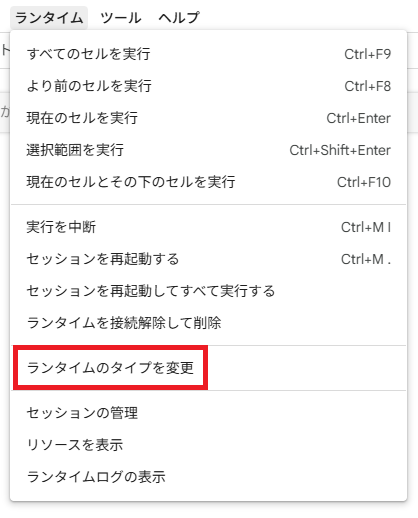
ここで任意のGPUを選択してください。無料版なら「T4 GPU」のみになります。有料版ならより高性能な「A100 GPU」と「L4 GPU」も選択できますが、アクセスするための「コンピューティングユニット」の消費が大きくなり、稼働させられる時間が短くなってしまいます。
加えて、「T4 GPU」ではVRAM不足によって1024*1024レベルの大きな解像度で生成することができません。有料版を購入したなら自分が生成したいものに合わせて上位のGPUを選択するとよいでしょう。
注意としては、ここを変更するとすべての設定がリセットされます。生成した画像を含め、モデルデータやLoRAなどのデータをアップロードしていた場合も、すべて最初からやり直しになってしまいます。
ランタイムのタイプはデフォルトの「Python 3」のままで問題ありません
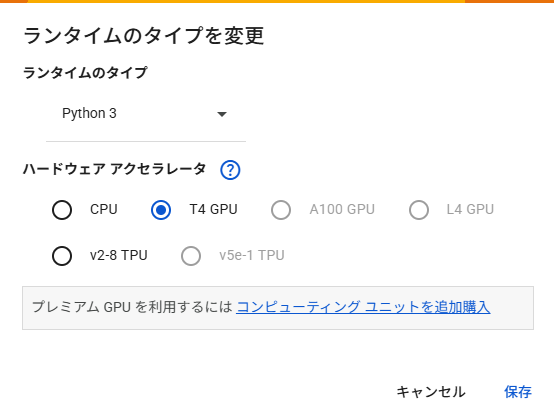
設定が済んだら次は「AUTOMATIC1111」のインストール準備になります。
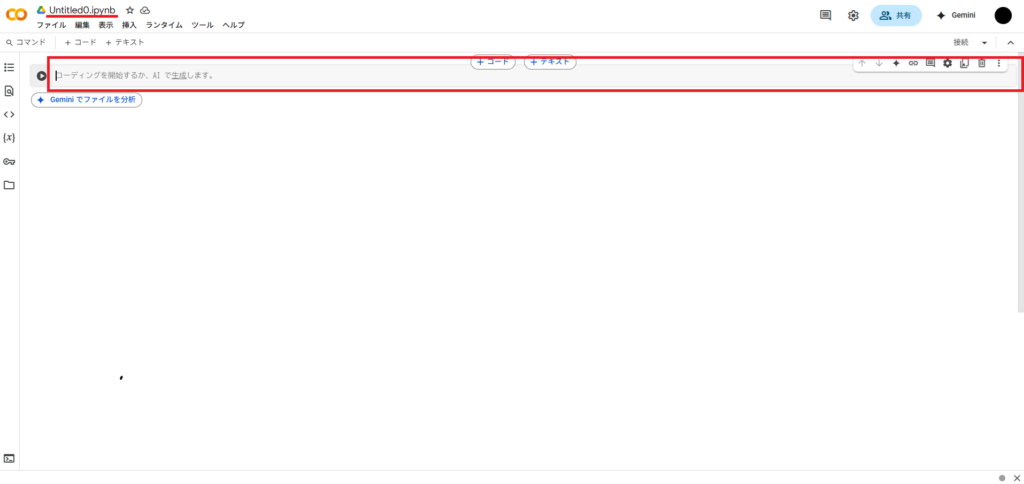
画面内の赤い四角で囲んだところがプログラムコードを入力する欄になりますので、そこに以下のコードを入力して、左側の三角ボタンを押して実行しましょう。
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
これは「GitHub」という、ソフトウェア開発のためにソースコードを管理できるプラットフォーム上で公開されている「AUTOMATIC1111」をGoogle Colab上にコピーするコードになります。
Stable Diffusionはよくあるソフトウェアのようにどこかにダウンロードリンクがあって、ファイルをダウンロードして実行といった形式ではありません。Pythonでコードを実行する必要があります。
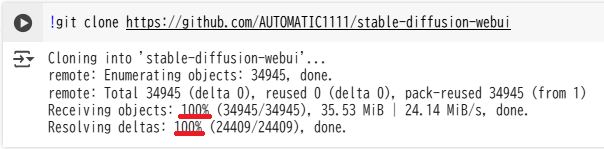
次に以下のコードで、「AUTOMATIC1111」のインストールと実行をします。
左上の「+コード」から新たな入力欄を追加して、実行してください。

%cd /content/stable-diffusion-webui
!python launch.py –share –enable-insecure-extension-access
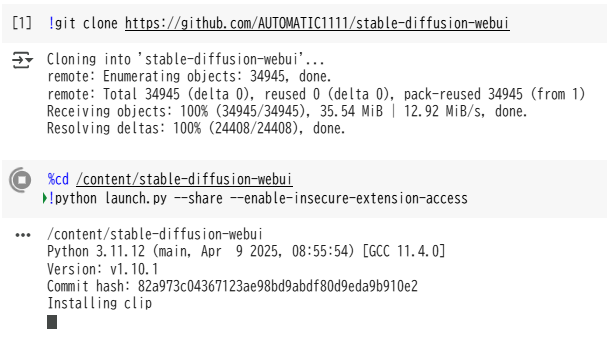
長々と出てきますが、下のほうにスクロールして「Running on public URL」と出てくれば起動完了ですので、このURLをクリックしましょう。

そうすると新しいタブで「AUTOMATIC1111」が開きます。
このセッションが接続されている限り、「コンピューティングユニット」が消費されていきます。使わない時間はGoogle Colabのタブに戻り、「ランタイム」タブから「ランタイムを接続解除して削除」することをおすすめしますが、切断するとインストールやアップロードしたもの、保存していない生成画像はすべて消えてしまいます。都度インストールからやり直さなければならないのがGoogle Colabの最大のデメリットともいえるでしょう。
一度設定してしまえば、次回開いたときにすでにコードの入力がされている状態になるので、順番に実行するだけで起動できます。
「コンピューティングユニット」の残数はGoogle Colab右上の「RAM」「ディスク」の隣の三角形から、「リソース」を選択すると確認できます。
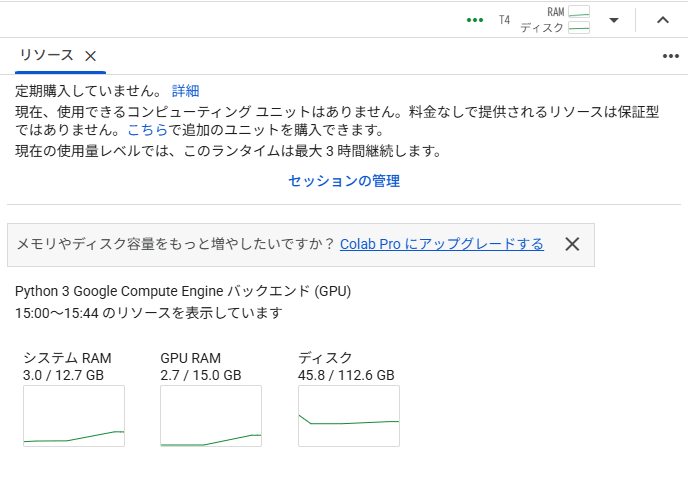
無料版ではGPUを利用できる時間に限りがあります。これはコンピューティングユニットとは違い、明記されていません。また、有料版のユーザーが優先的に利用できる仕様のため、使ってるうちにセッションを接続されてしまうこともあります。詳しくはGoogle Colabのサポート情報を確認してください。

無料版の上限に達すると、しばらくGPUを利用できなくなります。どれぐらい待てばまた利用可能になるのかも明記されていないため、有料版を購入したほうが快適に利用できるのは間違いありません。
Google Colaboratory よくある質問(外部サイト)

導入は以上になります。
利用方法
準備ができたら画像生成をしてみましょう。
その前に、AUTOMATIC1111には様々な機能が備わっています。今回は「とにかく画像生成をする」という点に絞って解説します。
なので、最初は思ったような画像が生成できないかもしれません。これは誰が悪いという訳ではなく、「AIの全力を引き出し切れていない」ということです。デフォルトで使えるモデルデータは特化した強みがなく、実写風でもアニメ風でも中途半端なものになりがちです。今回はGoogle colabの無料版という前提で話しますが、ここに由来する問題もあります。
また、UIは日本語化することもできますが、多くの解説記事などは英語UIを前提に解説しているところが多いため、翻訳するとかえって調べるときに不便になる可能性があります。Google Colabでは起動するたびに初期設定に戻ってしまうので、英語UIに慣れておきましょう。
まずは「画像生成できた」という体験だけ味わっていただければと思います。より詳しい解説は改めて行う予定ですので、ぜひチェックしてください。
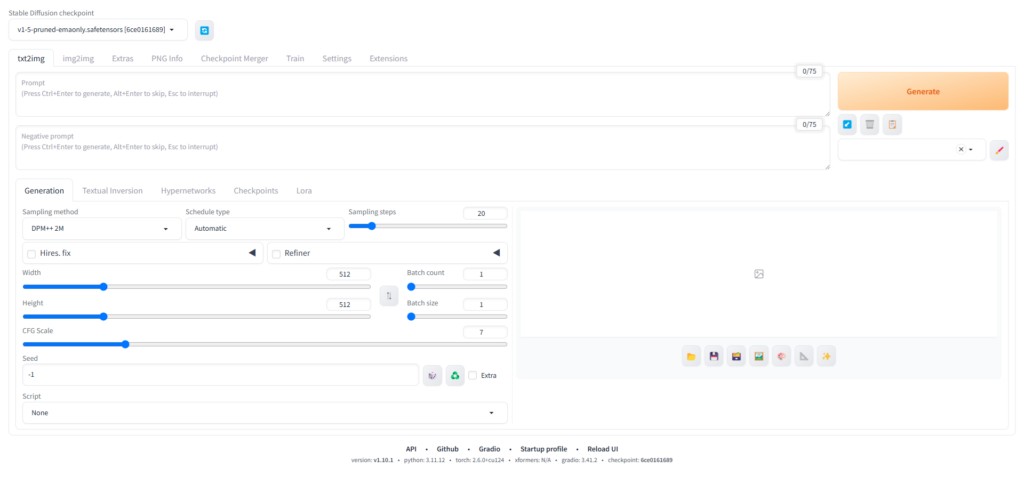
「Stable Diffusion checkpoint」
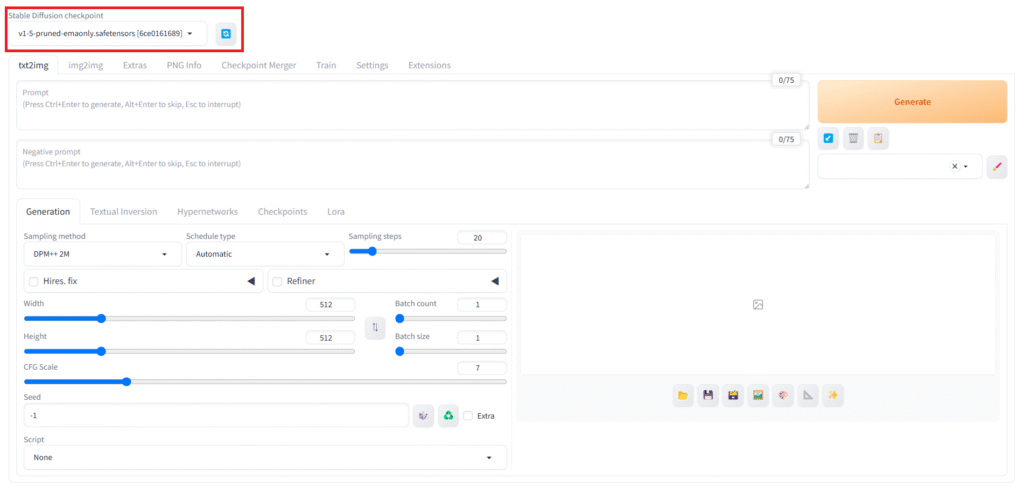
ここが「チェックポイント」と呼ばれるモデルデータを選択する欄です。もしアップロードしたモデルが表示されない場合は、右側の青いアイコンをクリックすると再読み込みされて、表示されるようになります。
もしモデルデータを持っている場合はGoogle Colabのページに行き、左側のフォルダアイコンをクリックし、「stable-diffusion-webui\models\stable-diffusion」内にアップロードすることで使用できるようになります。
「prompt(プロンプト)」「negative prompt(ネガティブプロンプト)」
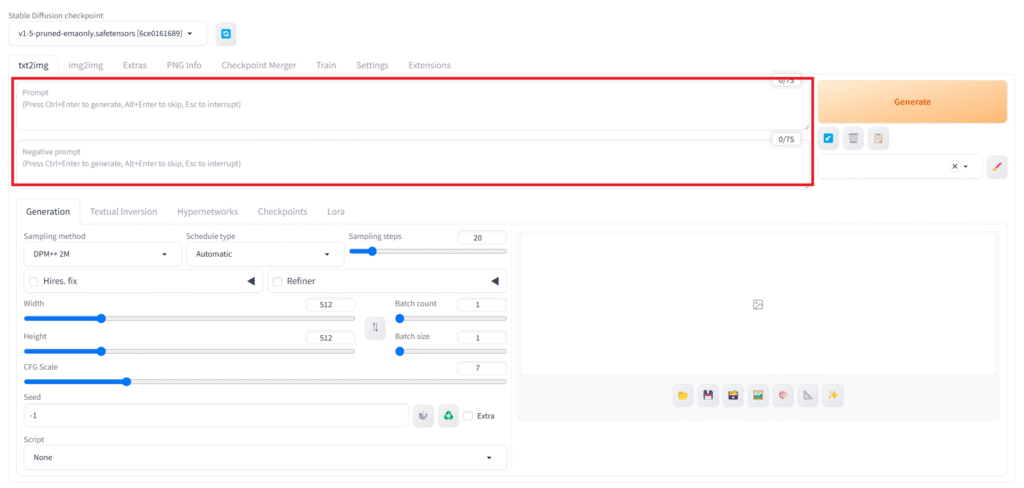
まずは「プロンプト」と「ネガティブプロンプト」を入力する欄になります。
プロンプトの入力方法については、過去の記事で解説していますので、そちらも併せてご確認ください。
画像生成はこの「プロンプト」が最重要と言えます。どんなに設定を整えても、プロンプトがいい加減だと思ったようなものを生成することはできません。(それをあえてガチャのように楽しむのも一つの手です。)
上の欄には出力してほしいものを、下の欄には出力してほしくない物を入力します。
「Sampling method」「Schedule type」
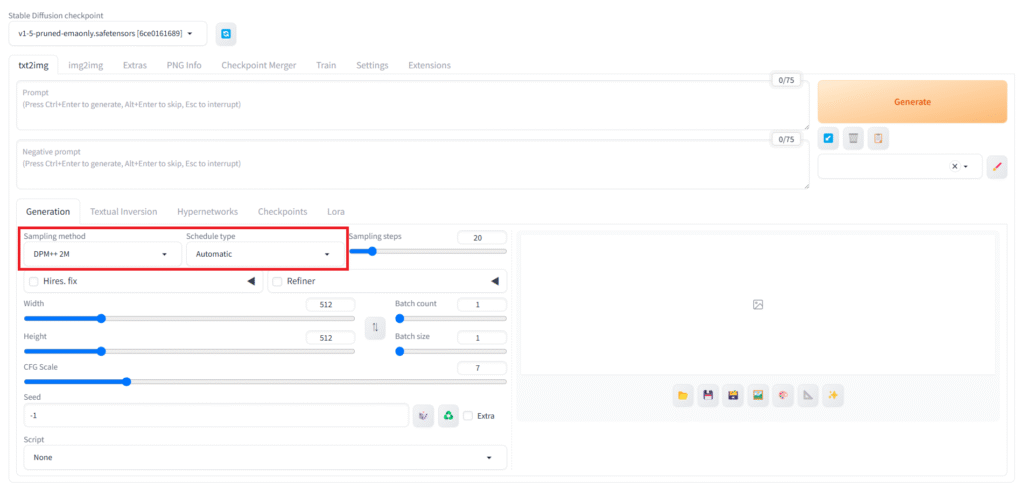
これは最初に説明した「拡散モデル」がノイズの集合から、どのように画像を生成するかの方法と手順の設定になります。
「Sampling method」
画像からノイズ除去をするための計算方法の種類です。それぞれ計算速度や得意な画風が異なります。掃除で例えるなら、モップなのか、掃除機なのか、ほうきなのかを選ぶイメージです。
「Schedule type」
ノイズ除去の進め方(ペース配分)です。「Sampling method」との組み合わせで画像の仕上がりが変わります。掃除で例えるなら、最初に一気にやるのか、後でまとめてやるのか、一定のペースを保ってやるのかを選ぶイメージです。
と言っても全然ピンと来ないとおもいますので、とりあえずは以下の設定がおすすめです
1.Sampling method:「DPM++ 2M」 Schedule type:「Karras」
2.Sampling method:「Euler A」 Schedule type:「automatic」
「karras」は「DPM++」系と相性がいいです。なめらかな画像生成ができます。「Euler A」も多くのモデルで推奨されています。Schedule typeの影響を受けにくいので、automaticで問題ないです。
使用するモデルによっては、推奨設定が存在する場合がありますので、これに従いましょう。
「Sampling steps」
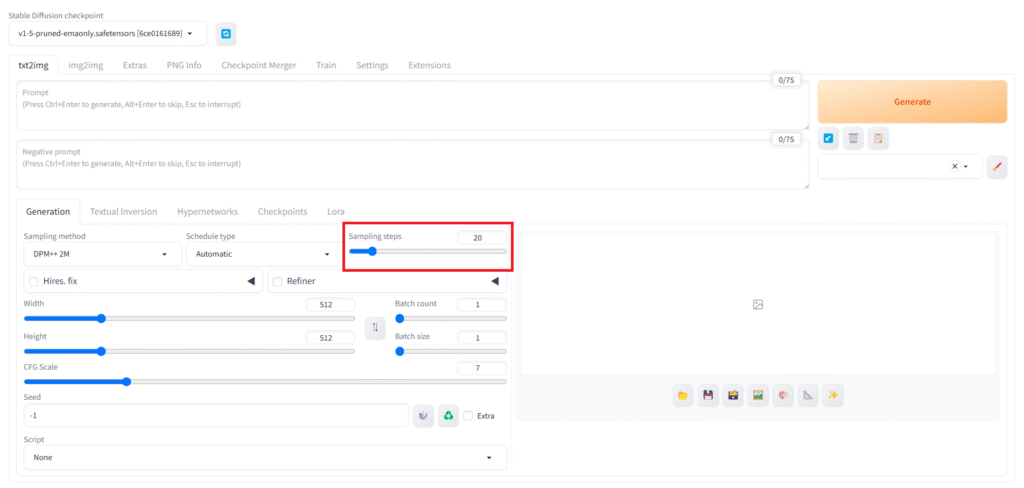
画像生成するにあたって、何回ノイズ除去を行うかの設定です。下げれば下げるほどノイズまみれのまま生成されるようになり、上げれば上げるほどきれいになる…というわけでもなく、一定以上の数値にしても、ある程度の品質以上にはならないため、処理時間やGPUにかかる負荷が増すだけになります。
おすすめは20~30程です。これもモデルデータによっては推奨設定がある場合があります。
「width」「height」
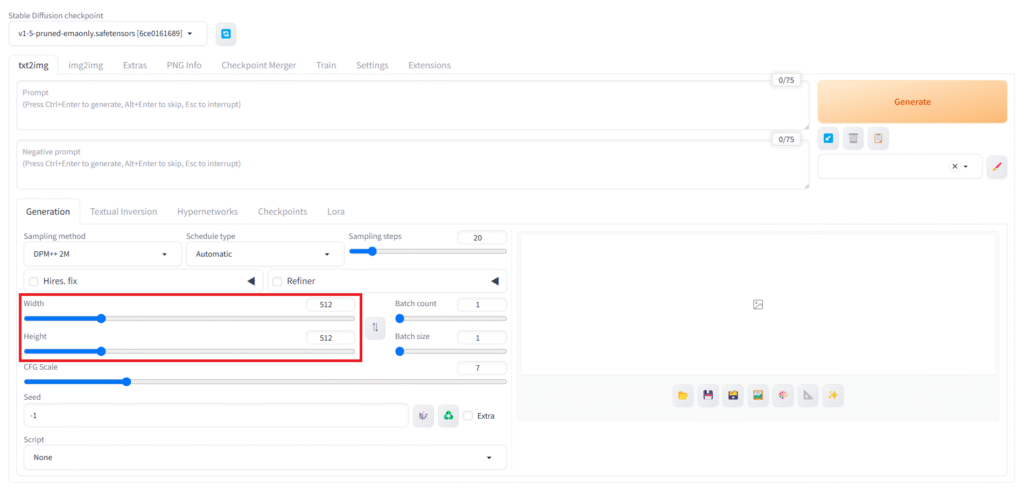
生成する画像のサイズを設定できます。
自由に設定できますが、モデルや、描きたい構図によって適したサイズが指定されていることもあります。
例えば、「立っている人の全身が映った画像」であれば縦長が適しており、横長にすると背景に余計なものが描かれてしまう可能性が高くなります。このように生成したい構図に合わせて比率を選択する必要があります。
また、デフォルトのモデルである「v1-5-pruned-emaonly」は「SD 1.5」系という古い規格のモデルであるため、512*512がサポートされており、解像度を高くすると破綻を起こしてしまう確率も高くなります。
逆に、現在メジャーに扱われている「SDXL」系や最新の「SD 3」系のモデルでは1024*1024を基本として学習しているため、512*512では破綻が大きくなる傾向にあります。
「T4 GPU」では1024*1024のレベルの解像度で生成するだけのVRAMを確保できないので、自然と「SDXL」系や「SD 3」系のモデルを使用するのは困難です。
機能として、数字は自由に入力できるようにはなっていますが、基本的には「8の倍数」に設定しておくのが安心です。これには多くのモデルが画像を効率的に学習するための手法が関わっています。
「CFG Scale」
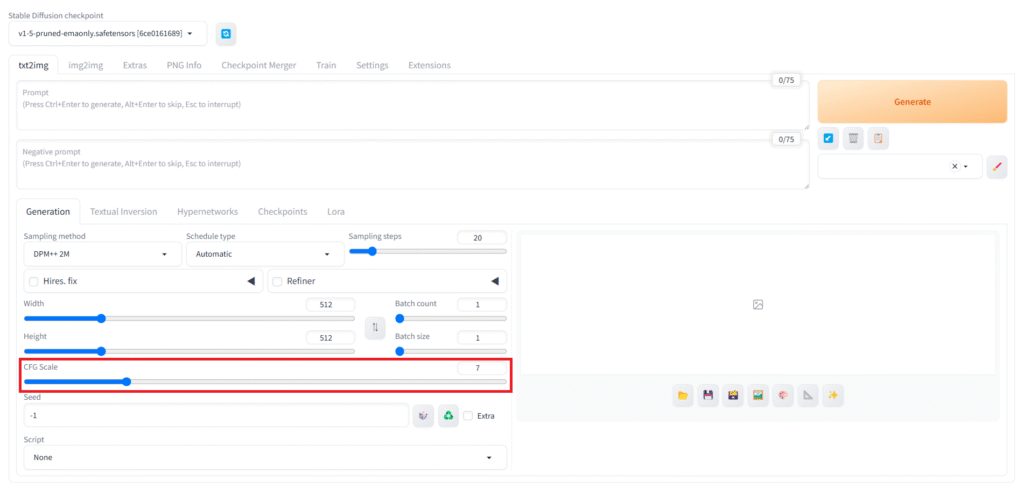
プロンプトにどれだけ忠実に従うかを設定できます。
低ければ生成画像の幅が広がり、高ければよりプロンプトの影響を強く受ける分、破綻しやすくなります。最初はデフォルトの7で試し、プロンプトの指示が弱いと感じたら少し上げ、画像が破綻するようなら少し下げてみましょう。モデルによっては推奨設定があることもあります。
CFGをどんなに上げてもプロンプトが反映されない時は、単純に誤字がある、モデルデータの学習元に、プロンプトが示すものが十分含まれていないといった原因がある可能性が高いです。
「Seed」
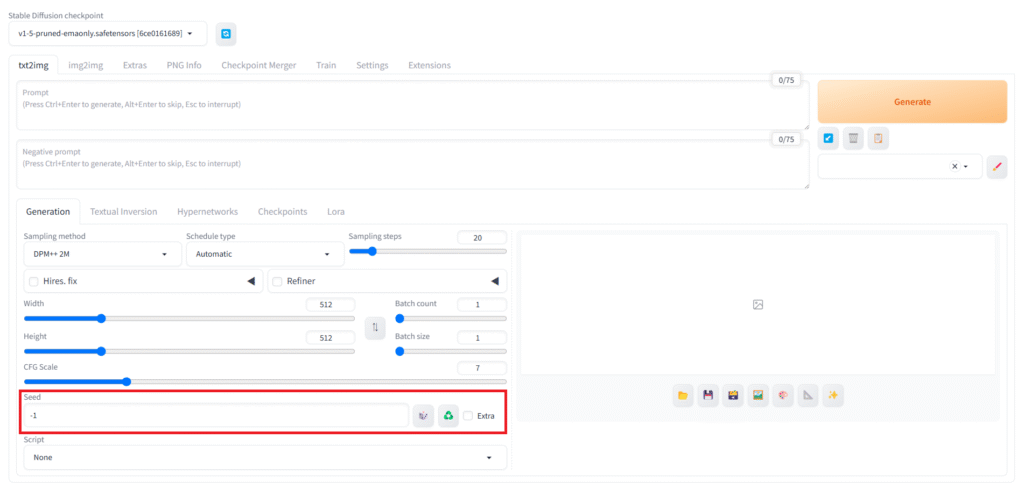
Seed値は生成のたびにランダムな結果を表示させるための機能です。
デフォルトでは「-1」が入力されており、これは生成のたびにランダムなSeed値が割り当てられるということを意味しています。
任意の数字を入力することで、そのSeed値に固定することができます。数字自体に意味はないので、適当に決めて大丈夫です。
隣にあるサイコロアイコンをクリックすると、-1に設定しなおすことができます。
緑の矢印アイコンをクリックすると、最後に生成した画像のSeed値を取得できます。
Seed値を固定すると、同じような結果が出やすくなります。「気に入ったけど少しだけ変えたい」という時には、その画像と同じSeed値を使用し、微調整するといった使い方ができます。
Seed値を含めて、全く同じ設定にすれば全く同じ画像を出力することができます。
「Batch count」「Batch size」
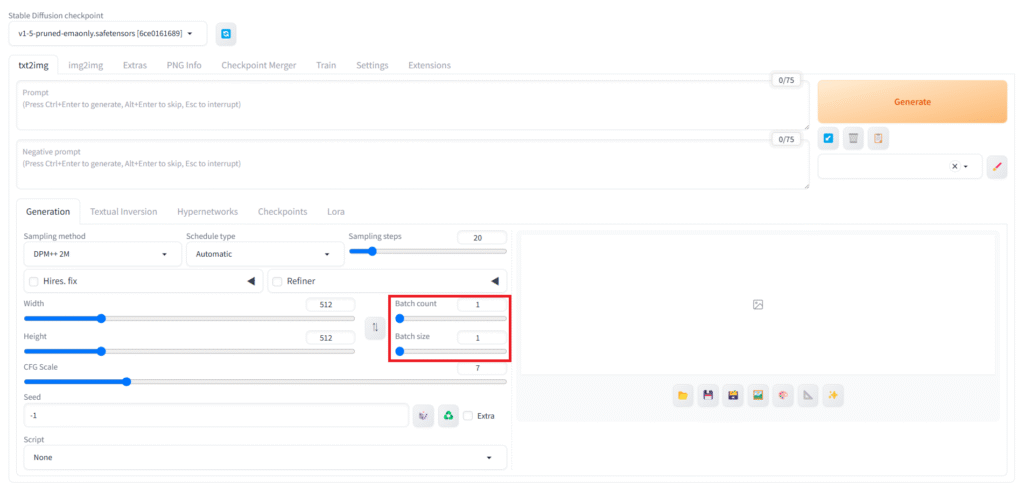
「Batch count」は何回連続で生成するかの設定です。例えば10に設定すれば、10枚をSeed値以外は同じ設定で次々と生成するので、その間に別の作業をすることもできます。
「Batch size」は何枚同時に生成するかの設定です。こちらは同時に処理が進むため、増やすとハイスペックGPUでなければ動作が重くなったり、エラーが出てしまう可能性があります。もし使っているGPUの性能が十分に高いのであれば、「Batch count」と合わせて効率よく大量に生成することができます。
ここまで設定出来たら、最後に右上の「Generate」をクリックして生成開始です。下の欄に生成された画像が表示されます。
これまでの解説のまとめ表です。
| パラメータ名 | 推奨設定 | 機能 |
|---|---|---|
| Sampling method | DPM++ 2M Euler A | ノイズ除去の計算方法。速度や得意な画風が異なる |
| Schedule type | Karras automatic | ノイズ除去の進め方。Sampling methodとの組み合わせで仕上がりが変わる |
| Sampling steps | 20~30 | ノイズ除去の回数。少ないとノイズが残りやすく、多すぎても品質向上は限定的で処理時間が増加 |
| Width / Height | 512*512 (SD1.5系) | 生成画像のサイズ。8の倍数が推奨。モデルにより適切な基本サイズがある(SDXL系は1024*1024) |
| CFG Scale | 7 (デフォルト) | プロンプトへの忠実度。低いと自由度が増し、高いと忠実になるが破綻しやすくなる |
| Seed | -1 (ランダム) | 生成結果のランダム性を制御。固定すると類似画像を生成しやすくなる |
| Batch count | 1~ | 連続生成回数 |
| Batch size | 1~ | 同時生成枚数。増やすとGPU負荷が高まる |
注意!
繰り返しにはなりますが、Google Colabではランタイムの接続を解除するたびに生成した画像もすべて消えてしまいます。気に入った画像は都度ローカルに保存するようにしましょう。
Google Colabのページに戻り、画面左端にあるフォルダアイコンをクリック。
「stable-diffusion-webui\outputs\txt2img-images\日付」に生成した画像が格納されています。
あるいは、生成された画像を右クリックして「名前を付けて保存」したり、画像下に並んでるアイコンのうち、左側のフォルダアイコンやフロッピーディスクアイコンから保存しましょう。(フロッピーディスクを知らない人は調べてね!)
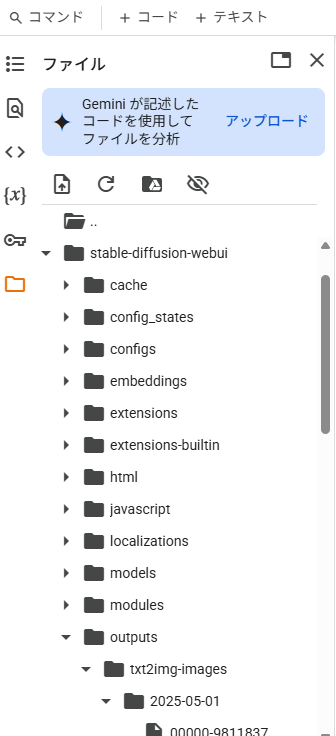
使い終わったら「ランタイムを接続解除して削除」をしましょう。この時点でアップロードしたすべてのデータや生成した画像が消えてしまいますが、接続を解除しないとコンピューティングユニットが消費され続けるので、無駄遣いを避けるために可能な限りまとめて作業して、終わったら消すを心がけましょう。
画像生成するための基本的な機能や設定の紹介は以上になります。
最後に
今回はStable Diffusionを利用するための1つの手段としてGoogle Colabを利用した「AUTOMATIC1111」の導入・利用方法をご紹介をしてきました。
Google Colab以外にも、GPUクラウドサービスは多く存在します。Google Colabとは違い、自分でPythonを導入するところから始めなければならないところもありますし、料金形態も様々です。
我々は今後も安心して利用できるサービスについて紹介していきます。
Stable Diffusion(AUTOMATIC1111)で生成した画像は多くの場合商用利用が可能ですが、AIによる画像生成は意図せず第三者の著作権・肖像権・商標権などを侵害するリスクもあります。また、モデルデータや追加学習データによっては商用利用を禁止していたり、商用利用以外でも公開の際にクレジット表記が求められる場合もありますので、公開・商用利用の際は、各モデルの利用規約や関連する法律を必ず確認してください。
最後にデフォルトで備わってるモデル「v1-5-pruned-emaonly」で何枚か画像生成をしてみましょう。
プロンプト
masterpiece, best quality, high quality, (animeとphotographicの2パターン試しました), 1girl, blue hair, wavy hair, medium hair, green eyes
ネガティブプロンプト
worst, bad, error, missing, extra








正直、微妙なクオリティです。きっと皆さんがよく目にするようなAIイラストのイメージには遠く及びません。プロンプトの効きも悪く、目や手に異常なまでの破綻が起こっています。これはモデルが学習したデータの質が低いためです。
高品質なモデルデータを使えば、同じプロンプトでも出来上がるイラストのクオリティの差は歴然です。




アニメ風、実写風でそれぞれに特化した別のモデルを使用しています。
こういったモデルの多くは「Civitai」というサイトでダウンロードできます。各モデルのダウンロードページに推奨設定や、商業利用などのライセンス表記が載っています。
モデル・LoRAデータの導入方法は以下の記事も併せてご確認ください。
その他の拡張機能の導入方法、利用方法などは別途まとめた記事を公開予定ですので、ぜひチェックしてください。



がもたらす「アンテザード・ソサエティ」の衝撃-300x200.png)




























